จาก Code สู่ความแม่นยำ: เบื้องหลังการทำงานของโปรเจกต์ Machine Learning นี้
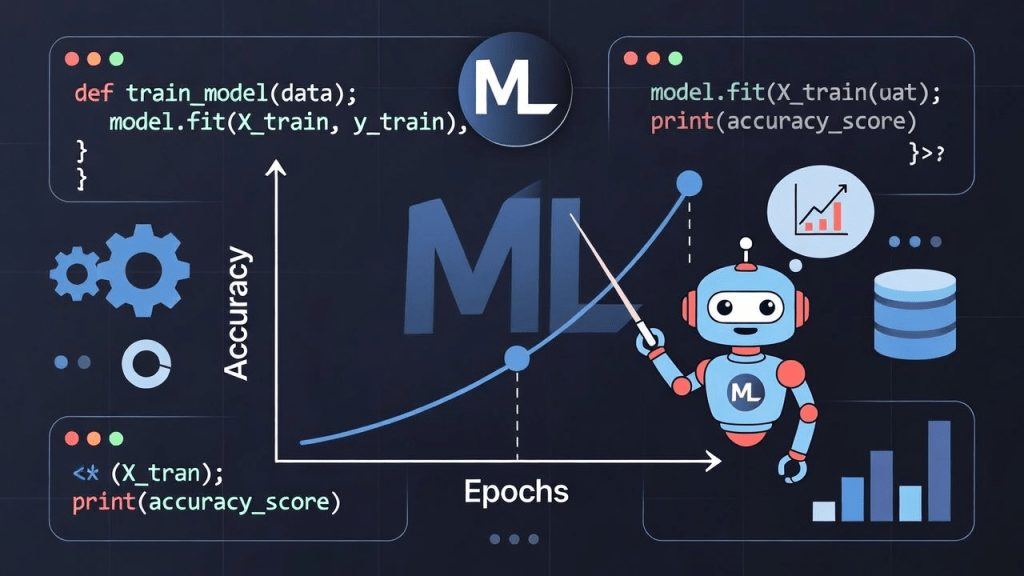
ในโลกที่ข้อมูลกลายเป็นทรัพยากรที่มีค่าที่สุด การนำข้อมูลเหล่านั้นมาแปรเปลี่ยนเป็นความรู้และปัญญาประดิษฐ์ (AI) ถือเป็นหัวใจสำคัญ ภาพประกอบด้านบนนี้ไม่ได้เป็นเพียงภาพกราฟิกสวยงาม แต่คือการสรุป Workflow หรือกระบวนการทำงานจริงภายในโปรเจกต์ Machine Learning ของเรา ตั้งแต่เริ่มต้นจนถึงผลลัพธ์สุดท้าย วันนี้เราจะมาเจาะลึกกันว่าแต่ละส่วนในภาพทำงานร่วมกันอย่างไรเพื่อให้ได้โมเดลที่มีประสิทธิภาพสูงที่สุด
1. ฟันเฟืองการเตรียมข้อมูลและการประมวลผล (The Machinery)
หากสังเกตที่มุมซ้ายล่างและด้านซ้ายกลางของภาพ คุณจะเห็น รูปฟันเฟือง (Gears) และ ฐานข้อมูล (Data Stack) สิ่งเหล่านี้เป็นตัวแทนของขั้นตอนที่สำคัญที่สุดนั่นคือ Data Engineering และ Feature Engineering
“Garbage In, Garbage Out” คือหลักการพื้นฐาน ข้อมูลที่ได้มามักจะดิบและไม่เป็นระเบียบ ฟันเฟืองเหล่านี้เปรียบเสมือนกระบวนการที่เราใช้ในการทำความสะอาดข้อมูล (Cleaning), แปลงค่า (Transformation), และคัดเลือกฟีเจอร์ที่สำคัญ (Feature Selection) เพื่อให้ข้อมูลพร้อมที่สุดก่อนจะส่งต่อให้โมเดลเรียนรู้ ซึ่งใน code snippet เล็กๆ มุมซ้ายล่าง (
X_tran) ก็แสดงถึงข้อมูลที่ผ่านการ Transform เรียบร้อยแล้ว
2. หัวใจหลัก: การฝึกฝนโมเดล (The Core Training Loop)
มุมซ้ายบนและขวาบนของภาพ แสดงตัวอย่าง code ภาษา Python ที่เป็นหัวใจหลักของการสร้าง AI:
def train_model(data);model.fit(X_train, y_train)
ส่วนนี้คือการนำข้อมูลที่เราเตรียมไว้ในขั้นแรกมา “สอน” โมเดล คำสั่ง .fit คือจุดที่ปาฏิหาริย์เกิดขึ้น! มันคือกระบวนการทางคณิตศาสตร์ที่โมเดลจะพยายามปรับเปลี่ยน parameter ภายในเพื่อลดข้อผิดพลาดลงเรื่อยๆ จนกระทั่งมันเริ่มเข้าใจรูปแบบ (Patterns) ของข้อมูลอย่างลึกซึ้ง
3. ผลลัพธ์: กราฟความแม่นยำและ Epochs (The Learning Curve)
กราฟขนาดใหญ่ตรงกลางคือ Performance Dashboard ของเรา:
- แกน X (Horizontal): คือ Epochs หรือจำนวนรอบที่โมเดลอ่านข้อมูลทั้งหมดหนึ่งรอบเพื่อเรียนรู้
- แกน Y (Vertical): คือ Accuracy หรือเปอร์เซ็นต์ความแม่นยำ
เส้นกราฟสีฟ้า ที่พุ่งขึ้นคือสิ่งที่นักพัฒนา ML ทุกคนอยากเห็น! มันแสดงให้เห็นว่ายิ่งเราปล่อยให้โมเดลเรียนรู้ไปหลายรอบ (Epochs เพิ่มขึ้น) ความแม่นยำ (Accuracy) ของโมเดลก็ยิ่งสูงขึ้นเรื่อยๆ ซึ่งนี่คือหลักฐานเชิงประจักษ์ว่าโมเดลของเรากำลัง “ฉลาดขึ้น” จริงๆ และไม่ได้เป็นเพียงการสุ่มเดา
4. ผู้ช่วยอัจฉริยะและการประเมินผล (The Agent & Evaluation)
สุดท้ายที่มุมขวา คือหุ่นยนต์มาสคอต ML Agent ที่ยืนชี้กราฟด้วยความภาคภูมิใจ หุ่นยนต์ตัวนี้เป็นตัวแทนของกระบวนการประเมินผล (Evaluation) และการนำไปใช้ (Deployment):
- เขากำลังชี้ไปที่จุดสูงสุดของกราฟ ซึ่งคือจุดที่โมเดลมีความแม่นยำสูงสุด (Optimal Accuracy)
- ด้านบนหุ่นยนต์มี code
print(accuracy_score)แสดงถึงผลลัพธ์ที่เป็นตัวเลขที่ใช้ยืนยันความสามารถของโมเดล - กราฟแท่งและกราฟย่อยด้านขวาล่าง คือการประเมินผลในมุมมองอื่นๆ เช่น Precision, Recall หรือ F1-Score เพื่อให้มั่นใจว่าโมเดลทำงานได้ดีในทุกมิติ
บทสรุป
ภาพประกอบนี้จึงไม่ใช่เพียงแค่ศิลปะ แต่คือการย่อโลกการพัฒนา Machine Learning ที่ซับซ้อนให้เข้าใจง่าย องค์ประกอบทุกอย่างตั้งแต่ Code -> การเตรียมข้อมูล -> การฝึกฝน -> การประเมินผลบนกราฟ คือฟันเฟืองที่ขาดไม่ได้เพื่อให้ได้ AI ที่แม่นยำและเชื่อถือได้ โปรเจกต์ของเรามุ่งเน้นการปรับแต่งในทุกกระบวนการเหล่านี้เพื่อให้มั่นใจว่าผลลัพธ์ที่ได้นั้นเป็น “The Best Optimal Model” อย่างที่เห็นในภาพ

Leave a comment